|
|
阅读本文前,请阅读相关说明,帮助您了解本系列文章
前文回顾
mmsegmentation源码阅读--FCN(一)
mmsegmentation源码阅读--FCN(二)
mmsegmentation源码阅读--FCN(三)
源码阅读
tools/test.py中比较比较重要的几个部分注释,其余不做解释
def parse_args():
parser = argparse.ArgumentParser(
description='mmseg test (and eval) a model')
parser.add_argument('--config', default='configs/fcn/fcn_r50-d8_512x512_80k_ade20k.py', help='test config file path')
parser.add_argument('--checkpoint', default='work_dirs/fcn_r50-d8_512x512_80k_ade20k/fcn_r50-d8_512x512_80k_ade20k.pth', help='checkpoint file')
parser.add_argument( # 指定工作目录
'--work-dir',
help=('if specified, the evaluation metric results will be dumped'
'into the directory as json'))
parser.add_argument( # 是否启用TTA
'--aug-test', action='store_true', help='Use Flip and Multi scale aug')
parser.add_argument('--out', help='output result file in pickle format') # 是否将检测结果以文件形式保存 output result file in pickle format
parser.add_argument( # 是否根据数据集要求格式化输出 相关函数位于数据集类中 Format the output results without perform evaluation
'--format-only',
action='store_true',
help='Format the output results without perform evaluation. It is'
'useful when you want to format the result to a specific format and '
'submit it to the test server')
parser.add_argument( # 验证指标
'--eval',
type=str,
nargs='+',
help='evaluation metrics, which depends on the dataset, e.g., "mIoU"'
' for generic datasets, and "cityscapes" for Cityscapes')
parser.add_argument('--show', action='store_true', help='show results') # 是否显示结果
parser.add_argument( # 保存结果路径
'--show-dir', help='directory where painted images will be saved')
parser.add_argument(
'--gpu-collect',
action='store_true',
help='whether to use gpu to collect results.')
parser.add_argument(
'--gpu-id',
type=int,
default=0,
help='id of gpu to use '
'(only applicable to non-distributed testing)')
parser.add_argument(
'--tmpdir',
help='tmp directory used for collecting results from multiple '
'workers, available when gpu_collect is not specified')
parser.add_argument(
'--options',
nargs='+',
action=DictAction,
help="--options is deprecated in favor of --cfg_options' and it will "
'not be supported in version v0.22.0. Override some settings in the '
'used config, the key-value pair in xxx=yyy format will be merged '
'into config file. If the value to be overwritten is a list, it '
'should be like key="[a,b]" or key=a,b It also allows nested '
'list/tuple values, e.g. key="[(a,b),(c,d)]" Note that the quotation '
'marks are necessary and that no white space is allowed.')
parser.add_argument(
'--cfg-options',
nargs='+',
action=DictAction,
help='override some settings in the used config, the key-value pair '
'in xxx=yyy format will be merged into config file. If the value to '
'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
'Note that the quotation marks are necessary and that no white space '
'is allowed.')
parser.add_argument(
'--eval-options',
nargs='+',
action=DictAction,
help='custom options for evaluation')
parser.add_argument(
'--launcher',
choices=['none', 'pytorch', 'slurm', 'mpi'],
default='none',
help='job launcher')
parser.add_argument( # 透明度默认为0.5
'--opacity',
type=float,
default=0.5,
help='Opacity of painted segmentation map. In (0, 1] range.')
parser.add_argument('--local_rank', type=int, default=0)
args = parser.parse_args()
if 'LOCAL_RANK' not in os.environ:
os.environ['LOCAL_RANK'] = str(args.local_rank)
if args.options and args.cfg_options:
raise ValueError(
'--options and --cfg-options cannot be both '
'specified, --options is deprecated in favor of --cfg-options. '
'--options will not be supported in version v0.22.0.')
if args.options:
warnings.warn('--options is deprecated in favor of --cfg-options. '
'--options will not be supported in version v0.22.0.')
args.cfg_options = args.options
return args
def main():
args = parse_args()
# 确保传参时至少指定一个
assert args.out or args.eval or args.format_only or args.show \
or args.show_dir, \
('Please specify at least one operation (save/eval/format/show the '
'results / save the results) with the argument "--out", "--eval"'
', "--format-only", "--show" or "--show-dir"')
if args.eval and args.format_only:
raise ValueError('--eval and --format_only cannot be both specified')
if args.out is not None and not args.out.endswith(('.pkl', '.pickle')):
raise ValueError('The output file must be a pkl file.')
cfg = mmcv.Config.fromfile(args.config)
if args.cfg_options is not None:
cfg.merge_from_dict(args.cfg_options)
# set multi-process settings
setup_multi_processes(cfg)
# set cudnn_benchmark
if cfg.get('cudnn_benchmark', False):
torch.backends.cudnn.benchmark = True
if args.aug_test: # 启用TTA
# hard code index
cfg.data.test.pipeline[1].img_ratios = [
0.5, 0.75, 1.0, 1.25, 1.5, 1.75
]
cfg.data.test.pipeline[1].flip = True
cfg.model.pretrained = None
cfg.data.test.test_mode = True
if args.gpu_id is not None:
cfg.gpu_ids = [args.gpu_id]
# init distributed env first, since logger depends on the dist info.
if args.launcher == 'none':
cfg.gpu_ids = [args.gpu_id]
distributed = False
if len(cfg.gpu_ids) > 1:
warnings.warn(f'The gpu-ids is reset from {cfg.gpu_ids} to '
f'{cfg.gpu_ids[0:1]} to avoid potential error in '
'non-distribute testing time.')
cfg.gpu_ids = cfg.gpu_ids[0:1]
else:
distributed = True
init_dist(args.launcher, **cfg.dist_params)
rank, _ = get_dist_info()
# allows not to create
if args.work_dir is not None and rank == 0:
mmcv.mkdir_or_exist(osp.abspath(args.work_dir))
timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
if args.aug_test:
json_file = osp.join(args.work_dir,
f'eval_multi_scale_{timestamp}.json')
else:
json_file = osp.join(args.work_dir,
f'eval_single_scale_{timestamp}.json')
elif rank == 0:
work_dir = osp.join('./work_dirs',
osp.splitext(osp.basename(args.config))[0])
mmcv.mkdir_or_exist(osp.abspath(work_dir))
timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
if args.aug_test:
json_file = osp.join(work_dir,
f'eval_multi_scale_{timestamp}.json')
else:
json_file = osp.join(work_dir,
f'eval_single_scale_{timestamp}.json')
# build the dataloader
# TODO: support multiple images per gpu (only minor changes are needed)
dataset = build_dataset(cfg.data.test)
# The default loader config
loader_cfg = dict(
# cfg.gpus will be ignored if distributed
num_gpus=len(cfg.gpu_ids),
dist=distributed,
shuffle=False)
# The overall dataloader settings
loader_cfg.update({
k: v
for k, v in cfg.data.items() if k not in [
'train', 'val', 'test', 'train_dataloader', 'val_dataloader',
'test_dataloader'
]
})
# 测试时默认一个GPU处理一张图像,故对于单GPU, 测试时batch size=1
test_loader_cfg = {
**loader_cfg,
'samples_per_gpu': 1,
'shuffle': False, # Not shuffle by default
**cfg.data.get('test_dataloader', {})
}
# build the dataloader
data_loader = build_dataloader(dataset, **test_loader_cfg)
# build the model and load checkpoint
cfg.model.train_cfg = None
model = build_segmentor(cfg.model, test_cfg=cfg.get('test_cfg'))
fp16_cfg = cfg.get('fp16', None)
if fp16_cfg is not None:
wrap_fp16_model(model)
checkpoint = load_checkpoint(model, args.checkpoint, map_location='cpu')
if 'CLASSES' in checkpoint.get('meta', {}):
model.CLASSES = checkpoint['meta']['CLASSES']
else:
print('"CLASSES" not found in meta, use dataset.CLASSES instead')
model.CLASSES = dataset.CLASSES
if 'PALETTE' in checkpoint.get('meta', {}):
model.PALETTE = checkpoint['meta']['PALETTE']
else:
print('"PALETTE" not found in meta, use dataset.PALETTE instead')
model.PALETTE = dataset.PALETTE
# clean gpu memory when starting a new evaluation.
torch.cuda.empty_cache()
eval_kwargs = {} if args.eval_options is None else args.eval_options
# Deprecated
efficient_test = eval_kwargs.get('efficient_test', False)
if efficient_test:
warnings.warn(
'``efficient_test=True`` does not have effect in tools/test.py, '
'the evaluation and format results are CPU memory efficient by '
'default')
eval_on_format_results = (
args.eval is not None and 'cityscapes' in args.eval)
if eval_on_format_results:
assert len(args.eval) == 1, 'eval on format results is not ' \
'applicable for metrics other than ' \
'cityscapes'
if args.format_only or eval_on_format_results:
if 'imgfile_prefix' in eval_kwargs:
tmpdir = eval_kwargs['imgfile_prefix']
else:
tmpdir = '.format_cityscapes'
eval_kwargs.setdefault('imgfile_prefix', tmpdir)
mmcv.mkdir_or_exist(tmpdir)
else:
tmpdir = None
cfg.device = get_device()
if not distributed: # 满足
warnings.warn(
'SyncBN is only supported with DDP. To be compatible with DP, '
'we convert SyncBN to BN. Please use dist_train.sh which can '
'avoid this error.')
if not torch.cuda.is_available():
assert digit_version(mmcv.__version__) >= digit_version('1.4.4'), \
'Please use MMCV >= 1.4.4 for CPU training!'
model = revert_sync_batchnorm(model)
model = build_dp(model, cfg.device, device_ids=cfg.gpu_ids)
results = single_gpu_test( # 单卡测试 该函数位于mmseg/apis/test.py
model,
data_loader,
args.show,
args.show_dir,
False,
args.opacity,
pre_eval=args.eval is not None and not eval_on_format_results,
format_only=args.format_only or eval_on_format_results,
format_args=eval_kwargs)
else:
model = build_ddp(
model,
cfg.device,
device_ids=[int(os.environ['LOCAL_RANK'])],
broadcast_buffers=False)
results = multi_gpu_test(
model,
data_loader,
args.tmpdir,
args.gpu_collect,
False,
pre_eval=args.eval is not None and not eval_on_format_results,
format_only=args.format_only or eval_on_format_results,
format_args=eval_kwargs)
rank, _ = get_dist_info()
if rank == 0:
if args.out:
warnings.warn(
'The behavior of ``args.out`` has been changed since MMSeg '
'v0.16, the pickled outputs could be seg map as type of '
'np.array, pre-eval results or file paths for '
'``dataset.format_results()``.')
print(f'\nwriting results to {args.out}')
mmcv.dump(results, args.out)
if args.eval:
eval_kwargs.update(metric=args.eval)
metric = dataset.evaluate(results, **eval_kwargs)
metric_dict = dict(config=args.config, metric=metric)
mmcv.dump(metric_dict, json_file, indent=4)
if tmpdir is not None and eval_on_format_results:
# remove tmp dir when cityscapes evaluation
shutil.rmtree(tmpdir)
if __name__ == '__main__':
main()
mmseg/apis/test.py中的single_gpu_test函数如下
def single_gpu_test(model,
data_loader,
show=False,
out_dir=None,
efficient_test=False,
opacity=0.5,
pre_eval=False,
format_only=False,
format_args={}):
if efficient_test: # 满足
warnings.warn(
'DeprecationWarning: ``efficient_test`` will be deprecated, the '
'evaluation is CPU memory friendly with pre_eval=True')
mmcv.mkdir_or_exist('.efficient_test')
# when none of them is set true, return segmentation results as
# a list of np.array.
assert [efficient_test, pre_eval, format_only].count(True) <= 1, \
&#39;``efficient_test``, ``pre_eval`` and ``format_only`` are mutually &#39; \
&#39;exclusive, only one of them could be true .&#39;
model.eval()
results = []
dataset = data_loader.dataset
prog_bar = mmcv.ProgressBar(len(dataset))
# The pipeline about how the data_loader retrieval samples from dataset:
# sampler -> batch_sampler -> indices
# The indices are passed to dataset_fetcher to get data from dataset.
# data_fetcher -> collate_fn(dataset[index]) -> data_sample
# we use batch_sampler to get correct data idx
loader_indices = data_loader.batch_sampler
for batch_indices, data in zip(loader_indices, data_loader):
with torch.no_grad():
# 读入数据,送入模型进行正向传播
# 根据前文可知,读入的数据data为一个字典Dict[str, List], 内部有两个元素img_metas和img
# List中元素个数为augmentation的个数,分别记录了一种augmentation后的img_meta和img
result = model(return_loss=False, **data)
if show or out_dir:
img_tensor = data[&#39;img&#39;][0]
img_metas = data[&#39;img_metas&#39;][0].data[0]
imgs = tensor2imgs(img_tensor, **img_metas[0][&#39;img_norm_cfg&#39;])
assert len(imgs) == len(img_metas)
for img, img_meta in zip(imgs, img_metas):
h, w, _ = img_meta[&#39;img_shape&#39;]
img_show = img[:h, :w, :]
ori_h, ori_w = img_meta[&#39;ori_shape&#39;][:-1]
img_show = mmcv.imresize(img_show, (ori_w, ori_h))
if out_dir:
out_file = osp.join(out_dir, img_meta[&#39;ori_filename&#39;])
else:
out_file = None
model.module.show_result(
img_show,
result,
palette=dataset.PALETTE,
show=show,
out_file=out_file,
opacity=opacity)
if efficient_test:
result = [np2tmp(_, tmpdir=&#39;.efficient_test&#39;) for _ in result]
if format_only:
result = dataset.format_results(
result, indices=batch_indices, **format_args)
if pre_eval:
# TODO: adapt samples_per_gpu > 1.
# only samples_per_gpu=1 valid now
result = dataset.pre_eval(result, indices=batch_indices)
results.extend(result)
else:
results.extend(result)
batch_size = len(result)
for _ in range(batch_size):
prog_bar.update()
return results继承体系: EncoderDecoder --> BaseSegmentor
正向传播从forward函数开始,该函数在BaseSegmentor类中。
class BaseSegmentor(BaseModule, metaclass=ABCMeta):
def __init__(self, init_cfg=None):
super(BaseSegmentor, self).__init__(init_cfg)
self.fp16_enabled = False
def forward_test(self, imgs, img_metas, **kwargs):
for var, name in [(imgs, &#39;imgs&#39;), (img_metas, &#39;img_metas&#39;)]:
if not isinstance(var, list):
raise TypeError(f&#39;{name} must be a list, but got &#39;
f&#39;{type(var)}&#39;)
num_augs = len(imgs) # 获取augmentation个数
if num_augs != len(img_metas):
raise ValueError(f&#39;num of augmentations ({len(imgs)}) != &#39;
f&#39;num of image meta ({len(img_metas)})&#39;)
# all images in the same aug batch all of the same ori_shape and pad
# shape
for img_meta in img_metas: # 遍历每种augmentation
ori_shapes = [_[&#39;ori_shape&#39;] for _ in img_meta]
assert all(shape == ori_shapes[0] for shape in ori_shapes)
img_shapes = [_[&#39;img_shape&#39;] for _ in img_meta]
assert all(shape == img_shapes[0] for shape in img_shapes)
pad_shapes = [_[&#39;pad_shape&#39;] for _ in img_meta]
assert all(shape == pad_shapes[0] for shape in pad_shapes)
if num_augs == 1:
return self.simple_test(imgs[0], img_metas[0], **kwargs)
else: # 满足
return self.aug_test(imgs, img_metas, **kwargs) # 调用EncoderDecoder类的EncoderDecoder类中实现了BaseSegmentor类中的aug_test方法,为此程序会去执行EncoderDecoder类中的该方法,如下
class EncoderDecoder(BaseSegmentor):
def __init__(self,
backbone,
decode_head,
neck=None,
auxiliary_head=None,
train_cfg=None,
test_cfg=None,
pretrained=None,
init_cfg=None):
super(EncoderDecoder, self).__init__(init_cfg)
if pretrained is not None:
assert backbone.get(&#39;pretrained&#39;) is None, \
&#39;both backbone and segmentor set pretrained weight&#39;
backbone.pretrained = pretrained
self.backbone = builder.build_backbone(backbone)
if neck is not None:
self.neck = builder.build_neck(neck)
self._init_decode_head(decode_head)
self._init_auxiliary_head(auxiliary_head)
self.train_cfg = train_cfg
self.test_cfg = test_cfg
assert self.with_decode_head
def aug_test(self, imgs, img_metas, rescale=True):
# aug_test rescale all imgs back to ori_shape for now
assert rescale
# to save memory, we get augmented seg logit inplace 采用inplace节约内存
seg_logit = self.inference(imgs[0], img_metas[0], rescale)
for i in range(1, len(imgs)):
cur_seg_logit = self.inference(imgs, img_metas, rescale)
seg_logit += cur_seg_logit # 将每种augmentation的结果加在一起
seg_logit /= len(imgs) # 取平均
if self.out_channels == 1:
seg_pred = (seg_logit >
self.decode_head.threshold).to(seg_logit).squeeze(1)
else:
seg_pred = seg_logit.argmax(dim=1) # 获取对应label
seg_pred = seg_pred.cpu().numpy() # [1, H, W]
# unravel batch dim
seg_pred = list(seg_pred) # 去除了batch维度
return seg_pred
def inference(self, img, img_meta, rescale):
assert self.test_cfg.mode in [&#39;slide&#39;, &#39;whole&#39;]
ori_shape = img_meta[0][&#39;ori_shape&#39;] # 获取原图尺寸
assert all(_[&#39;ori_shape&#39;] == ori_shape for _ in img_meta)
if self.test_cfg.mode == &#39;slide&#39;:
seg_logit = self.slide_inference(img, img_meta, rescale)
else: # 由配置文件 满足
seg_logit = self.whole_inference(img, img_meta, rescale)
if self.out_channels == 1:
output = F.sigmoid(seg_logit)
else: # 多分类 满足
output = F.softmax(seg_logit, dim=1)
flip = img_meta[0][&#39;flip&#39;] # 如果存在flip,则恢复
if flip:
flip_direction = img_meta[0][&#39;flip_direction&#39;]
assert flip_direction in [&#39;horizontal&#39;, &#39;vertical&#39;]
if flip_direction == &#39;horizontal&#39;:
output = output.flip(dims=(3, ))
elif flip_direction == &#39;vertical&#39;:
output = output.flip(dims=(2, ))
return output
def whole_inference(self, img, img_meta, rescale):
seg_logit = self.encode_decode(img, img_meta) # [1, num_class, H, W]
if rescale: # 满足
# support dynamic shape for onnx
if torch.onnx.is_in_onnx_export():
size = img.shape[2:]
else:
# remove padding area
resize_shape = img_meta[0][&#39;img_shape&#39;][:2]
seg_logit = seg_logit[:, :, :resize_shape[0], :resize_shape[1]] # 去除padding
size = img_meta[0][&#39;ori_shape&#39;][:2]
seg_logit = resize( # resize到原图尺寸
seg_logit,
size=size,
mode=&#39;bilinear&#39;,
align_corners=self.align_corners,
warning=False)
return seg_logit
def encode_decode(self, img, img_metas):
x = self.extract_feat(img) # 同训练流程中完全一致,不再赘述 提取特征
out = self._decode_head_forward_test(x, img_metas) # [1, num_class, H/8, W/8]
out = resize( #上采样 [1, num_class, H/8, W/8] --> [1, num_class, H, W]
input=out,
size=img.shape[2:],
mode=&#39;bilinear&#39;,
align_corners=self.align_corners)
return out
def extract_feat(self, img):
x = self.backbone(img)
if self.with_neck:
x = self.neck(x)
return x
def _decode_head_forward_test(self, x, img_metas):
seg_logits = self.decode_head.forward_test(x, img_metas, self.test_cfg) # 调用FCNHead中forward_test
return seg_logits # [1, num_class, H/8, W/8]
# 该配置文件下未使用,在这也作出解析
def slide_inference(self, img, img_meta, rescale):
h_stride, w_stride = self.test_cfg.stride
h_crop, w_crop = self.test_cfg.crop_size
batch_size, _, h_img, w_img = img.size()
out_channels = self.out_channels
h_grids = max(h_img - h_crop + h_stride - 1, 0) // h_stride + 1
w_grids = max(w_img - w_crop + w_stride - 1, 0) // w_stride + 1
preds = img.new_zeros((batch_size, out_channels, h_img, w_img)) # 记录预测结果
count_mat = img.new_zeros((batch_size, 1, h_img, w_img)) # 记录每个pixel经过正向传播的次数
for h_idx in range(h_grids): # 遍历每个slide位置
for w_idx in range(w_grids):
y1 = h_idx * h_stride
x1 = w_idx * w_stride
y2 = min(y1 + h_crop, h_img)
x2 = min(x1 + w_crop, w_img)
y1 = max(y2 - h_crop, 0)
x1 = max(x2 - w_crop, 0)
crop_img = img[:, :, y1:y2, x1:x2]
crop_seg_logit = self.encode_decode(crop_img, img_meta)
preds += F.pad(crop_seg_logit, # 左右上下pad 0
(int(x1), int(preds.shape[3] - x2), int(y1),
int(preds.shape[2] - y2)))
count_mat[:, :, y1:y2, x1:x2] += 1
assert (count_mat == 0).sum() == 0 # 确保每个区域都经过了正向传播
if torch.onnx.is_in_onnx_export():
# cast count_mat to constant while exporting to ONNX
count_mat = torch.from_numpy(
count_mat.cpu().detach().numpy()).to(device=img.device)
preds = preds / count_mat # 取平均
if rescale: # 满足
# remove padding area
resize_shape = img_meta[0][&#39;img_shape&#39;][:2]
preds = preds[:, :, :resize_shape[0], :resize_shape[1]] # 去除padding
preds = resize( # resize到原图尺寸
preds,
size=img_meta[0][&#39;ori_shape&#39;][:2],
mode=&#39;bilinear&#39;,
align_corners=self.align_corners,
warning=False)
return predsFCNHead类中forward_test方法,如下
class FCNHead(BaseDecodeHead):
def __init__(self,
num_convs=2,
kernel_size=3,
concat_input=True,
dilation=1,
**kwargs):
assert num_convs >= 0 and dilation > 0 and isinstance(dilation, int)
self.num_convs = num_convs
self.concat_input = concat_input
self.kernel_size = kernel_size
super(FCNHead, self).__init__(**kwargs)
if num_convs == 0:
assert self.in_channels == self.channels
conv_padding = (kernel_size // 2) * dilation
convs = []
for i in range(num_convs):
_in_channels = self.in_channels if i == 0 else self.channels
convs.append(
ConvModule(
_in_channels,
self.channels,
kernel_size=kernel_size,
padding=conv_padding,
dilation=dilation,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg))
if len(convs) == 0:
self.convs = nn.Identity()
else:
self.convs = nn.Sequential(*convs)
if self.concat_input:
self.conv_cat = ConvModule(
self.in_channels + self.channels,
self.channels,
kernel_size=kernel_size,
padding=kernel_size // 2,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
def forward_test(self, inputs, img_metas, test_cfg):
return self.forward(inputs) # 调用forward 同训练流程中一致 不再赘述
slide推理模式如下
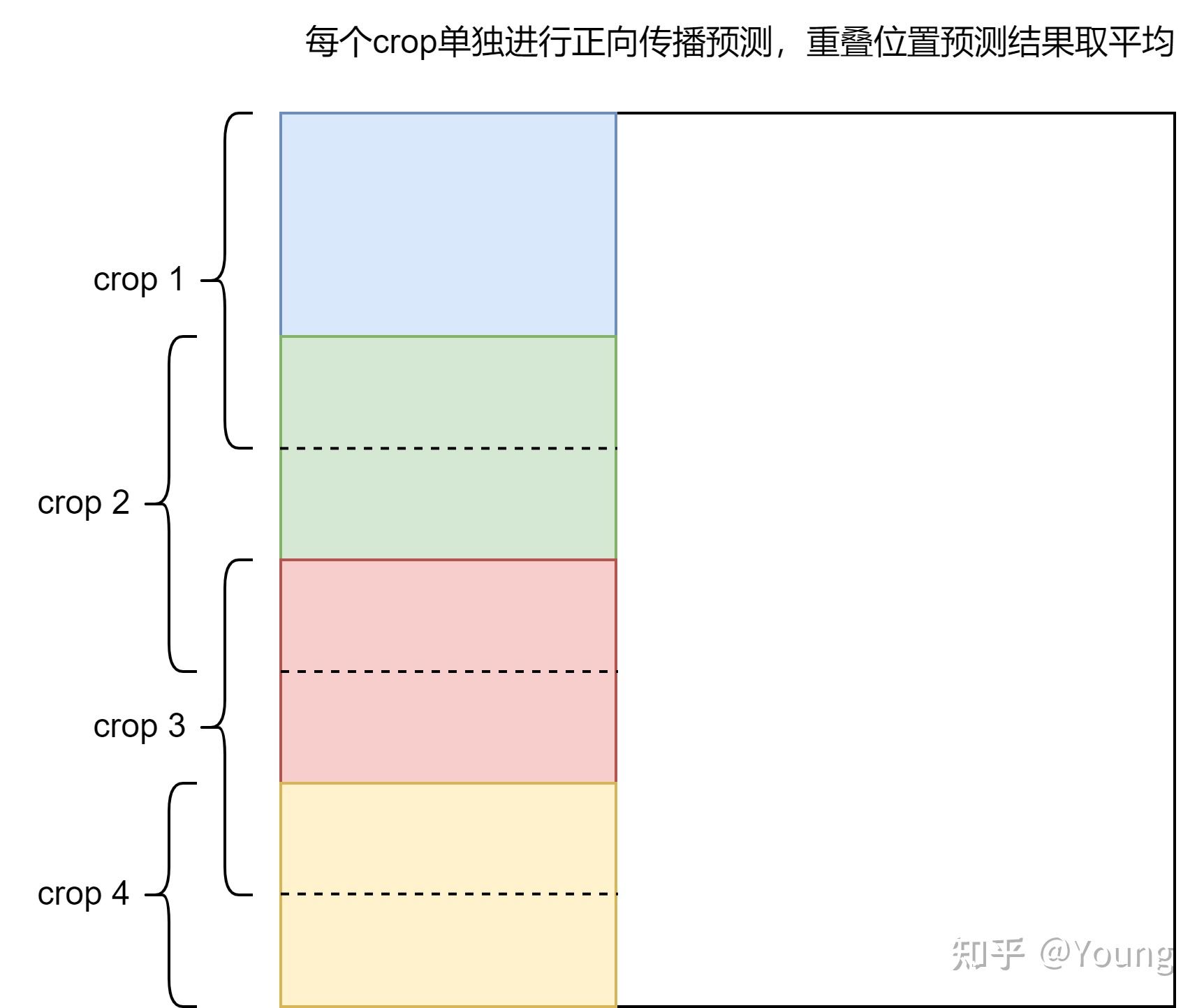
至此,测试流程结束,获得最终检测结果为一个List[ndarray],shape为[H, W],内部存储分割结果 |
|



 发表于 2022-11-27 12:27:33
发表于 2022-11-27 12:27:33