|
|
本文是个人根据B站大佬Bubbliiiing的FRCNN系列视频同步完成FRCNN训练,记录心得和遇见的问题。
关于RCNN家族的对比,本人有一篇博客或许能为大家答疑解惑RCNN学习笔记[1]—— RCNN 系列对比 - 知乎 (zhihu.com)该代码实现的Faster RCNN网络的backbone是Resnet-50,本人写过一篇resnet-x网络的代码详解,可供参考。
1. 前期准备
- 所使用的代码工程文件请见:faster rcnn: faster rcnn训练资源 (gitee.com)
Github链接:isolateFeng/faster-rcnn: faster-rcnn网络训练代码 (github.com)
百度网盘链接:https://pan.baidu.com/s/1FgZLVoGgS6ujpuLwUYFjPQ?pwd=5x5f 提取码:5x5f
- 本人相关配置:python3.8 + torch1.6 + torchvision0.7 + cuda10.1其中torch和torchvision均为gpu版本
这里有本人下载好的配合py38使用的 gpu版torch1.6+torchvision0.7 whl文件,然后使用本地安装即可
链接:https://pan.baidu.com/s/1sjqN8MEEBkUdnDE509efpg?pwd=laud 提取码:laud
- 训练所需的voc_weights_resnet.pth或者voc_weights_vgg.pth以及主干的网络权重
网络权重链接: https://pan.baidu.com/s/1S6wG8sEXBeoSec95NZxmlQ
提取码: 8mgp
voc_weights_resnet.pth(resnet为主干特征提取网络)和voc_weights_vgg.pth(是vgg为主干特征提取网络)都是已经训练好的frcnn网络参数,直接在预测(predicit.py)中使用 resnet50-19c8e357.pth和vgg16-397923af.pth是已经训练好的backbone网络参数,在自己使用自己的数据集或自己重新开始训练时使用,这部分属于预训练好的网络,属于fine tuning技术,加快网络的收敛
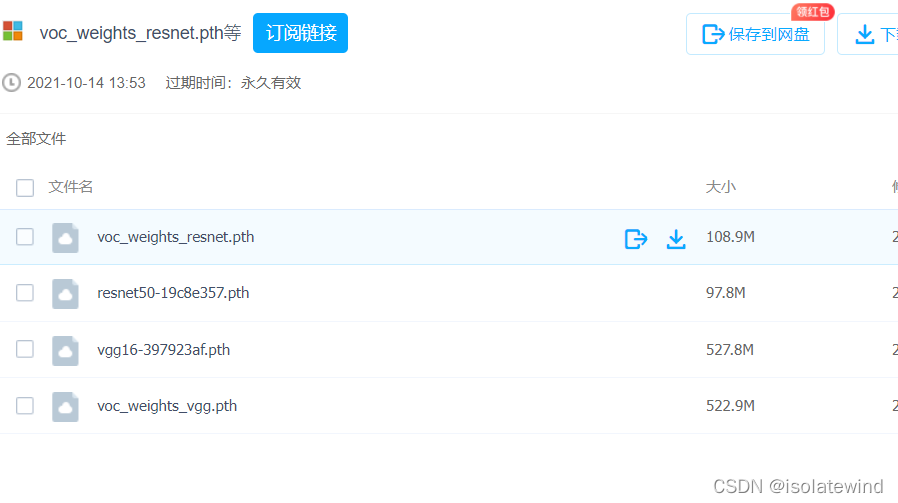
下载好后,放入model_data 文件夹
VOC数据集下载地址如下,里面已经包括了训练集、测试集、验证集(与测试集一样),无需再次划分:
链接: https://pan.baidu.com/s/1YuBbBKxm2FGgTU5OfaeC5A
提取码: uack
该数据集下载好后解压,直接放入工程文件中,和train.py等文件同路径
2. 代码使用
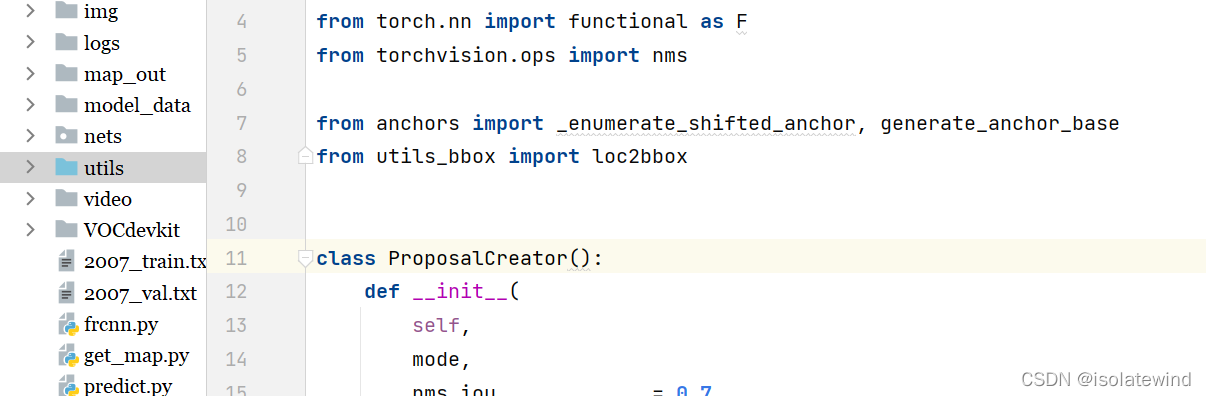
请参考:Pytorch 搭建自己的Faster-RCNN目标检测平台(Bubbliiiing 深度学习 教程)_哔哩哔哩_bilibili 在faster rcnn: faster rcnn训练资源 (gitee.com)下载好源码和上述工程文件后,打开文件可能发现某些代码报错(如下图),无法引用到另外一个文件夹中的代码文件
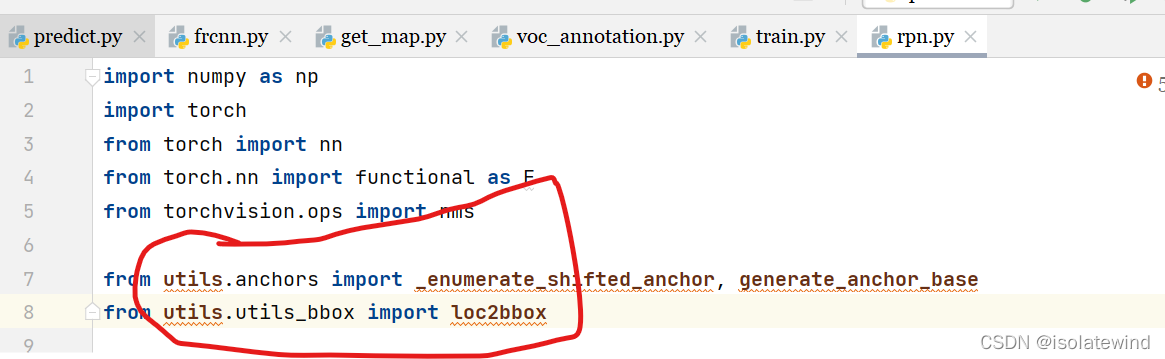
如果你使用的是pycharm,你可以按下图操作
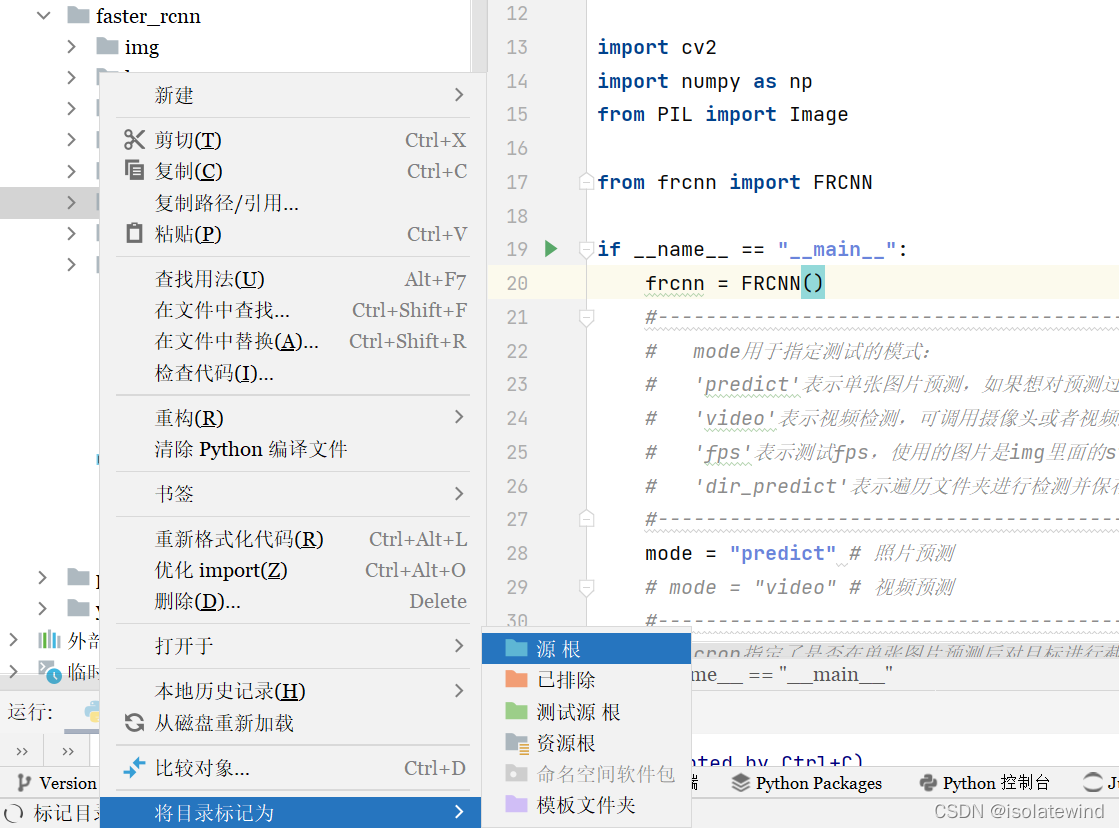
对utils文件夹右键 -> 将目录标记为 源根 -> 再去除报错代码中的文件名,如下
3. 预测步骤
拿到代码和过程文件后肯定会想先使用一下,测试一下效果,所以我们先介绍预测过程的代码使用。
在预测过程中,只会使用到根目录下的predict.py和frcnn.py
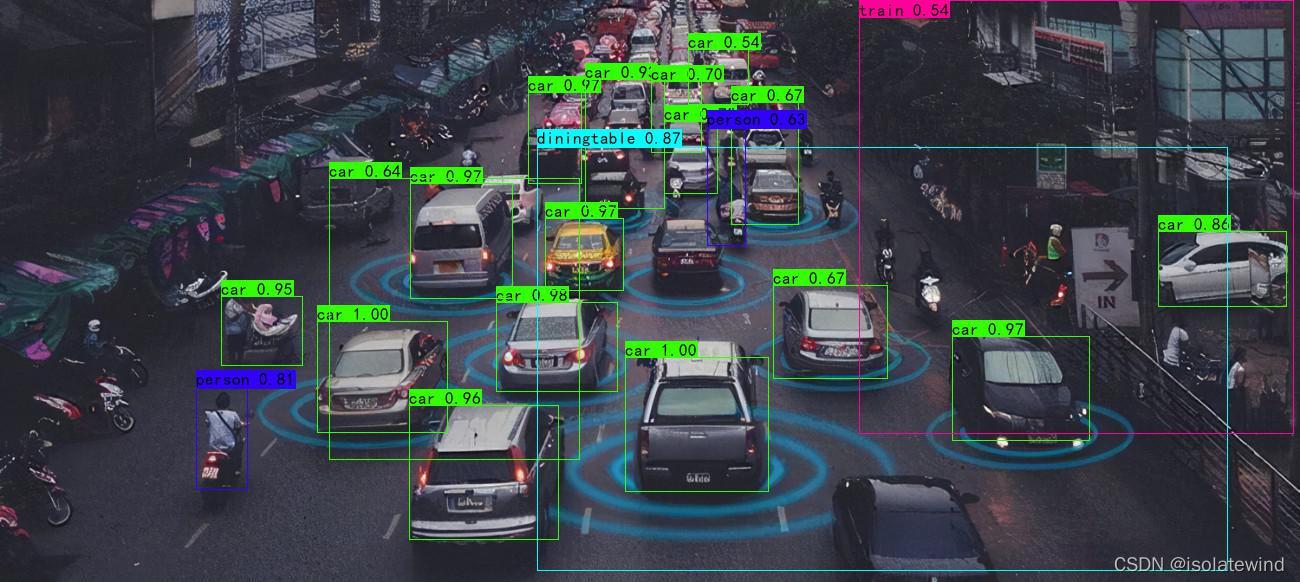
3.1 直接使用预先训练好的权重
- 在百度网盘下载frcnn_weights.pth,放入model_data,运行predict.py,输入
img/test5.jpg2. 在predict.py里面进行设置可以进行fps测试和video视频检测。
输入原图:img/test5.jpg

输出处理后的结果
3.2 使用自己训练好的权重
- 按照下文的训练步骤,获得生成在logs文件夹中的pth文件
2. 在frcnn.py文件里面,在如下部分修改model_path和classes_path使其对应训练好的文件;
model_path对应logs文件夹下面的权值文件,classes_path是model_path对应分的类。
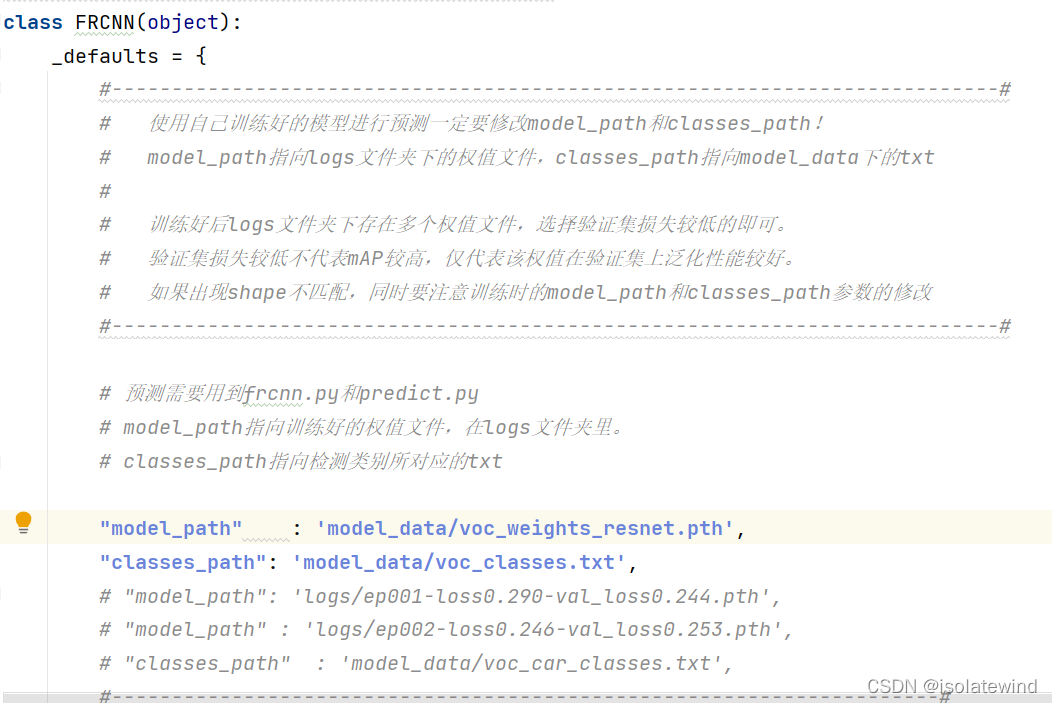
在frcnn.py文件修改model_path和classes_path,如果是使用网络上下载下来预先训练好的权重,就使用
"model_path" : 'model_data/voc_weights_resnet.pth',
"classes_path" : 'model_data/voc_classes.txt',反之,要使用自己训练得到的权重(运行train.py后会保存在logs目录下),就使用
"model_path" : 'logs/ep002-loss0.246-val_loss0.253.pth', # logs/ + 文件名
"classes_path" : 'model_data/voc_car_classes.txt',3. 运行predict.py,输入
img/test5.jpg4. 在predict.py里面进行设置可以进行fps测试和video视频检测。
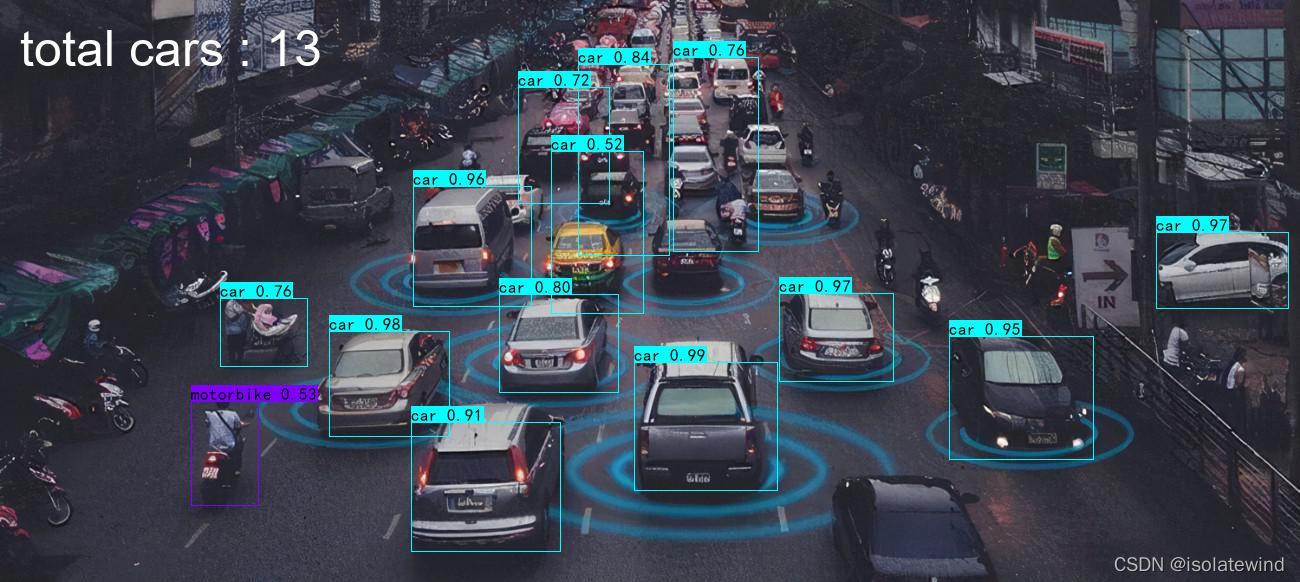
以下展示一下自己训练的权重使用,本人只训练网络去识别交通工具的类别(具体看model_data文件夹下的voc_car_classes.txt文件,并统计图片中车子的数量)
4. 训练步骤
4.1 训练VOC07+12数据集
本文使用VOC格式进行训练,训练前需要下载好VOC07+12的数据集,解压后放在根目录
VOC07+12的数据集 链接: https://pan.baidu.com/s/1YuBbBKxm2FGgTU5OfaeC5A 提取码: uack 2. 数据集的处理
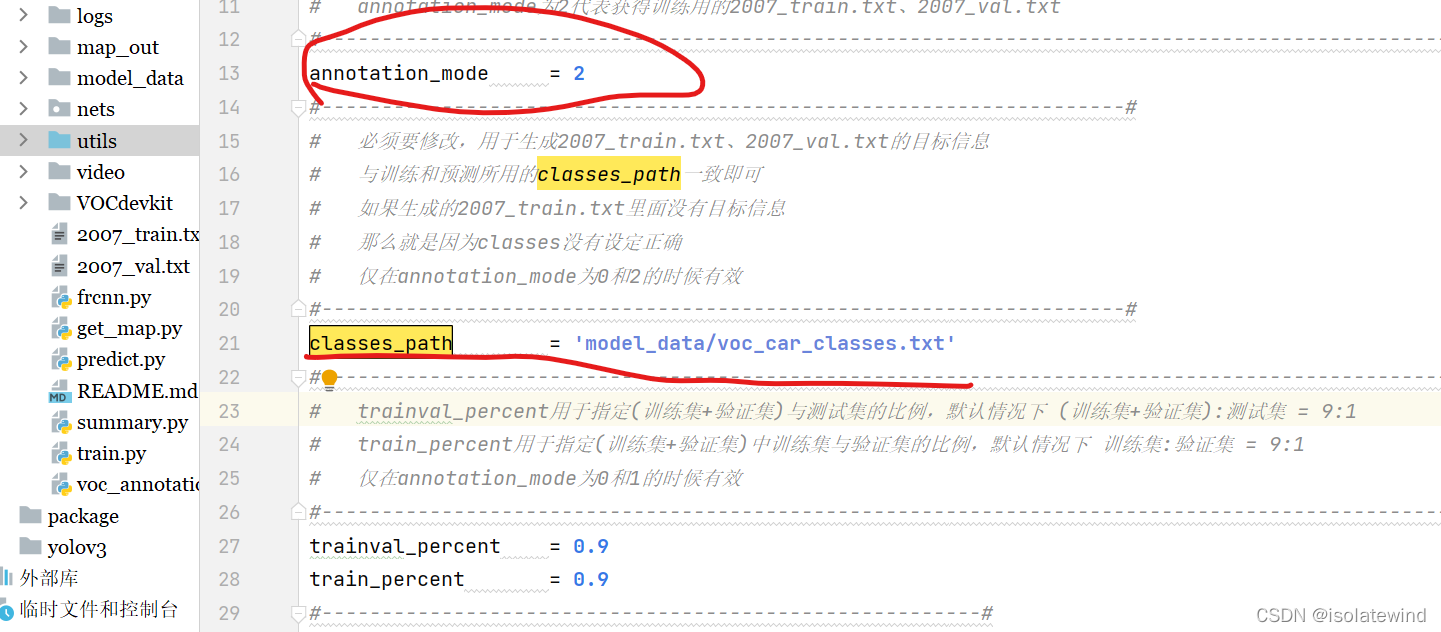
修改voc_annotation.py里面的annotation_mode=2,运行voc_annotation.py生成根目录下的2007_train.txt和2007_val.txt。
3. 开始网络训练
train.py的默认参数用于训练VOC数据集,直接运行train.py即可开始训练。
4. 训练结果预测
训练结果预测需要用到两个文件,分别是frcnn.py和predict.py。
我们首先需要去frcnn.py里面修改model_path以及classes_path,这两个参数必须要修改。
model_path指向训练好的权值文件,在logs文件夹里。
classes_path指向检测类别所对应的txt。
完成修改后就可以运行predict.py进行检测了。运行后输入图片路径即可检测。
4.2 训练自己的数据集
本文使用VOC格式进行训练,训练前需要自己制作好数据集
训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中。
训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。
(如果仍使用VOC数据集,只是限制识别种类,可以跳过这步)
2. 数据集的处理
在完成数据集的摆放之后,我们需要利用voc_annotation.py获得训练用的2007_train.txt和2007_val.txt。
修改voc_annotation.py里面的参数。第一次训练可以仅修改classes_path,classes_path用于指向检测类别所对应的txt。
训练自己的数据集时,可以自己建立一个cls_classes.txt,里面写自己所需要区分的类别
例如我在训练自己的数据集时,我就想训练一个只识别交通工具并统计出识别到的汽车(car)数量的网络,model_data/voc_car_classes.txt文件内容为:
bicycle
bus
car
motorbike修改voc_annotation.py中的classes_path,使其对应model_data/voc_car_classes.tx,并运行voc_annotation.py。
3. 开始网络训练
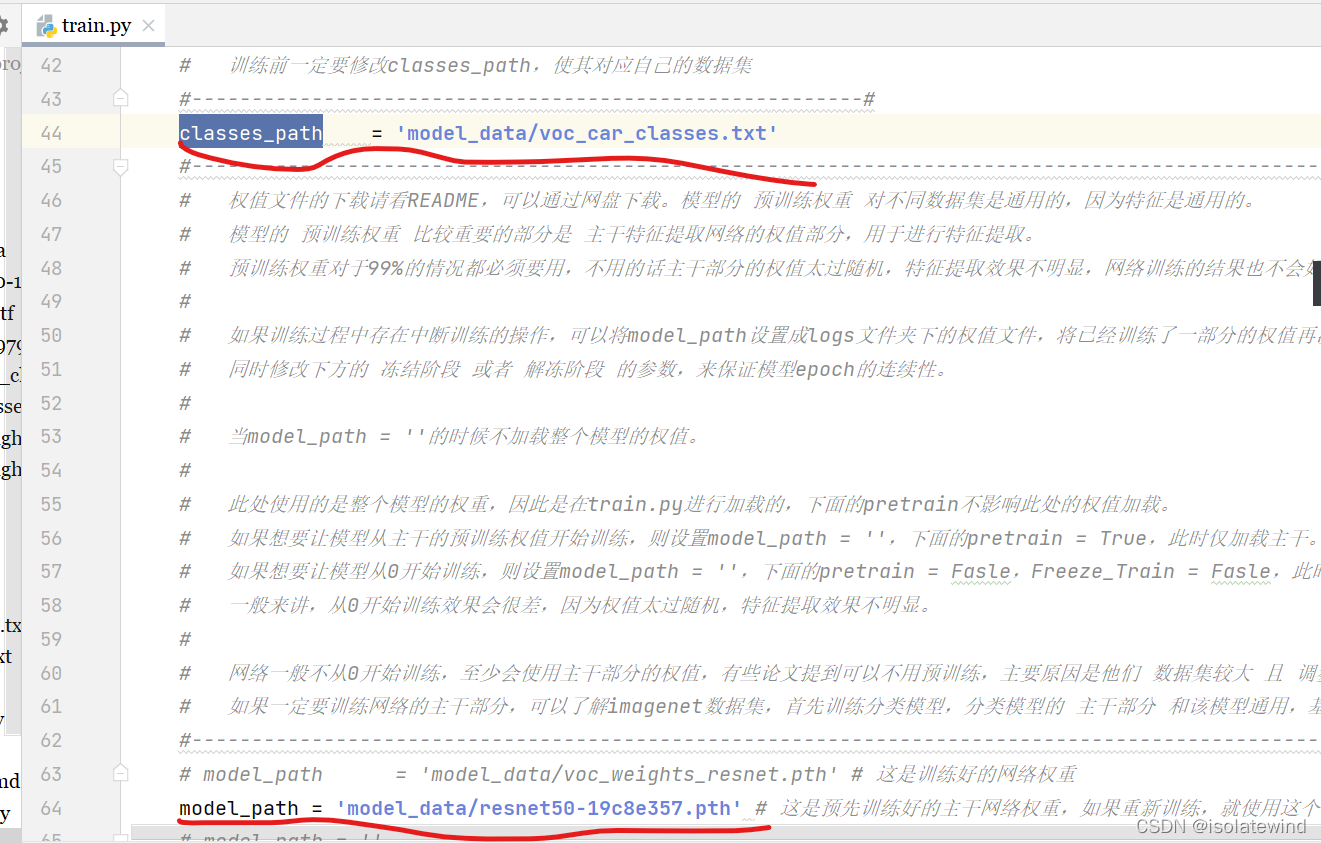
训练的参数较多,均在train.py中,大家可以在下载库后仔细看注释,其中最重要的部分依然是train.py里的classes_path和model_path。
classes_path用于指向检测类别所对应的txt,这个txt和voc_annotation.py里面的txt一样!训练自己的数据集必须要修改!
model_path是提前预训练好的主干网络权重,接下来使用VOC数据集进行训练即可,这样收敛快
修改完classes_path后就可以运行train.py开始训练了,在训练多个epoch后,权值会生成在logs文件夹中。
4. 训练结果预测
训练结果预测需要用到两个文件,分别是frcnn.py和predict.py。在frcnn.py里面修改model_path以及classes_path。
model_path指向训练好的权值文件,在logs文件夹里。
classes_path指向检测类别所对应的txt。
完成修改后就可以运行predict.py进行检测了,运行后输入图片路径即可检测。
例如:自己使用model_data/voc_car_classes.txt生成的数据集,训练好的权重文件路径是 logs/ep002-loss0.246-val_loss0.253.pth
"model_path" : 'logs/ep002-loss0.246-val_loss0.253.pth', # logs/ + 文件名
"classes_path" : 'model_data/voc_car_classes.txt',5. 在predict.py里面进行设置可以进行fps测试和video视频检测。
5. 评估步骤
5.1 评估VOC07+12的测试集
- 本文使用VOC格式进行评估。VOC07+12已经划分好了测试集,无需利用voc_annotation.py生成ImageSets文件夹下的txt。
- 在frcnn.py里面修改model_path以及classes_path。model_path指向训练好的权值文件,在logs文件夹里。classes_path指向检测类别所对应的txt。
- 运行get_map.py即可获得评估结果,评估结果会保存在map_out文件夹中。
5.2 评估自己的数据集
2. 如果在训练前已经运行过voc_annotation.py文件,代码会自动将数据集划分成训练集、验证集和测试集。如果想要修改测试集的比例,可以修改voc_annotation.py文件下的trainval_percent。
trainval_percent用于指定(训练集+验证集)与测试集的比例,默认情况下 (训练集+验证集):测试集 = 9:1。train_percent用于指定(训练集+验证集)中训练集与验证集的比例,默认情况下 训练集:验证集 = 9:1。 3. 利用voc_annotation.py划分测试集后,前往get_map.py文件修改classes_path,classes_path用于指向检测类别所对应的txt,这个txt和训练时的txt一样。评估自己的数据集必须要修改。
4. 在frcnn.py里面修改model_path以及classes_path。model_path指向训练好的权值文件,在logs文件夹里。classes_path指向检测类别所对应的txt。
5. 运行get_map.py即可获得评估结果,评估结果会保存在map_out文件夹中。
6. 个人训练心得
- 详细阅读代码中的注释文件,结合视频Pytorch 搭建自己的Faster-RCNN目标检测平台(Bubbliiiing 深度学习 教程)_哔哩哔哩_bilibili学习
本人关于主干网络(backbone)中的Resnet-x写了一篇源码解读,有需要的同学请转:Resnet-x代码详解_isolatewind的博客-CSDN博客
- 很多问题都是环境配置出错,配置相应的python+torch+torchvision十分重要
- 个人训练想法:让网络只识别交通工具类(bicycle、bus、car、motorbike)物体,并输出识别到的car数量
所需步骤:
(1) 在model_data文件夹中新建voc_car_classes.txt文件,内容为:
bicycle
bus
car
motorbike(2) 在voc_annotation.py文件中设定
annotation_mode = 2 # 获得训练用的2007_train.txt、2007_val.txt
classes_path = 'model_data/voc_car_classes.txt'(3) 在train.py文件中设定
classes_path = 'model_data/voc_car_classes.txt'
model_path = 'model_data/resnet50-19c8e357.pth' # 加载主干resnet-50的权值,相当于进行了预训练
# 其他参数视训练效果调整此时不需要设定 pretrained = True,因为这个设定也只是在网络上下载主干网络的权值resnet50-19c8e357.pth,而且速度很慢
(4) 每一轮训练大概耗时1.5h(显卡:GTX1050Ti),每一轮的训练结果都会保存在logs文件夹下,如图
(5) 进入预测阶段
在frcnnn.py文件中设定
# "model_path" : 'model_data/voc_weights_resnet.pth',
# "classes_path": 'model_data/voc_classes.txt',
"model_path": 'logs/ep001-loss0.290-val_loss0.244.pth',
"classes_path" : 'model_data/voc_car_classes.txt',并在图像绘制部分(从192行左右开始),修改为以下代码,以此实现 检测车辆数据
#---------------------------------------------------------#
# 图像绘制
#---------------------------------------------------------#
count_car = 0 # 检测车辆数据
for i, c in list(enumerate(top_label)):
predicted_class = self.class_names[int(c)]
if predicted_class == 'car':
count_car += 1
box = top_boxes
score = top_conf
top, left, bottom, right = box
top = max(0, np.floor(top).astype('int32'))
left = max(0, np.floor(left).astype('int32'))
bottom = min(image.size[1], np.floor(bottom).astype('int32'))
right = min(image.size[0], np.floor(right).astype('int32'))
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
label = label.encode('utf-8')
# print(label, top, left, bottom, right)
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
for i in range(thickness):
draw.rectangle([left + i, top + i, right - i, bottom - i], outline=self.colors[c])
draw.rectangle([tuple(text_origin), tuple(text_origin + label_size)], fill=self.colors[c])
draw.text(text_origin, str(label,'UTF-8'), fill=(0, 0, 0), font=font)
del draw
# 标记检测车辆数据
draw = ImageDraw.Draw(image)
font1 = ImageFont.truetype(r'C:\Users\System-Pc\Desktop\arial.ttf', 50)
count_num = 'total cars : {} '.format(count_car)
count_num = count_num.encode('utf-8')
draw.text((20, 20), str(count_num, 'UTF-8'), fill=(255, 255, 255), font=font1)
del draw
return image运行 predict.py,具体步骤参考 3. 预测步骤
输入: img/test5.jpg
效果如下:
|
|



 发表于 2022-9-22 18:45:13
发表于 2022-9-22 18:45:13